CPU Cache是什么
CPU Cache是在内存的基础上,可以被CPU直接读取的缓存,分为 L1,L2,L3 三层缓存级别,他的读取速度,是内存的100倍以上,我们都知道基于内存的数据库Redis,仅仅是使用了内存存储就很快了,CPU Cache则更快,利用好CPU Cache则可以让你编写的程序更快。
相比较各类IO操作,CPU Cache则是最底层的,分级一般为 L1 Cache > L2 Cache > L3 Cache > MEM > SSD > HDD,按照现在市场上面的定价,相对应的价格也是梯形下降
相对于CPU Cache昂贵的价格,带来的收益自然也要更高,可以通过如下命令查看所在机器的CPU Cache分别是多少,从而更有利于优化代码
1 | 获取L1 数据缓存大小 |
一般来说 L3 的容量 > L2 > L1数据 = L1指令
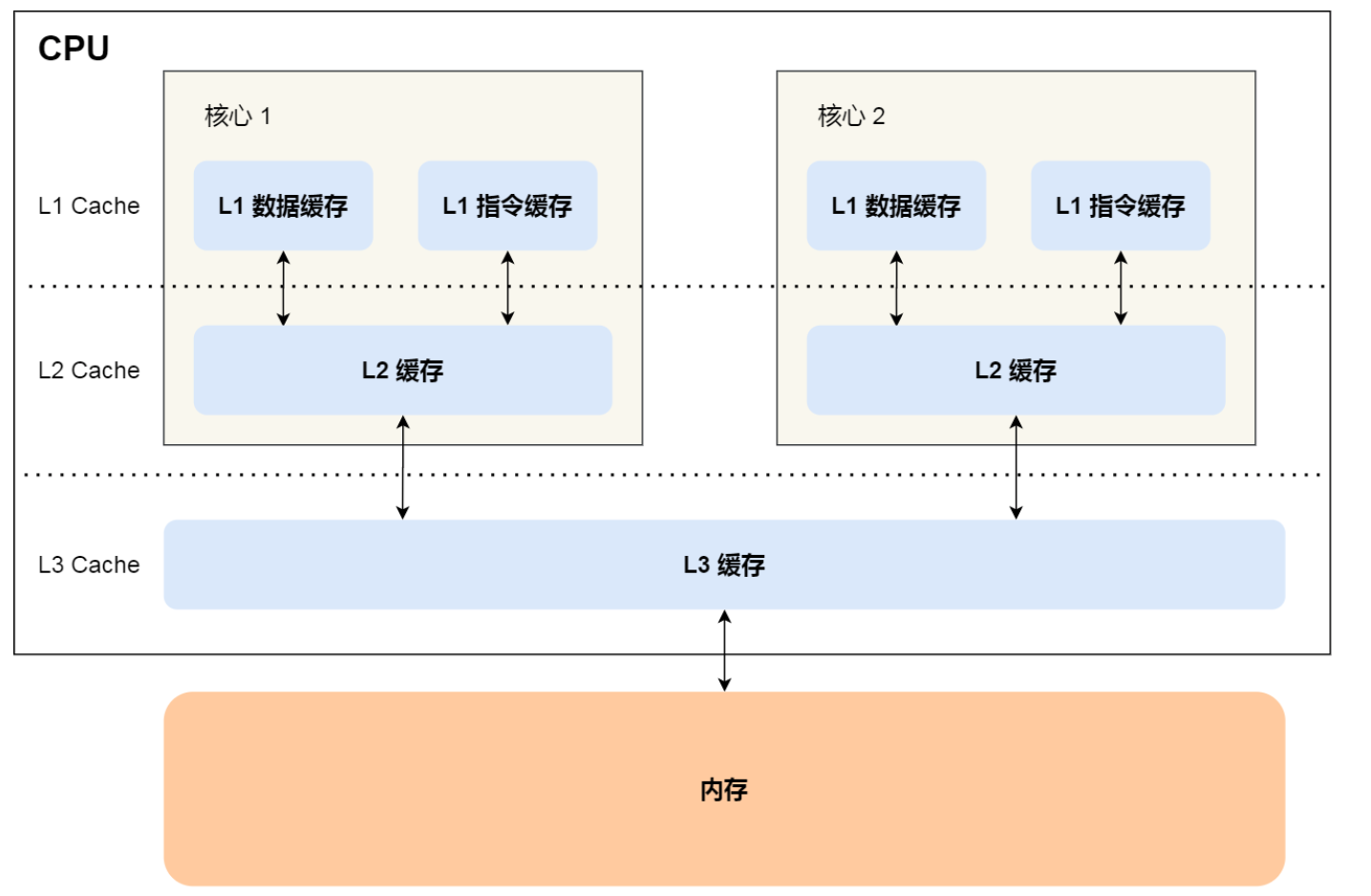
越靠近 CPU 核心的缓存其访问速度越快,CPU 访问 L1 Cache 只需要 24 个时钟周期,访问 L2 Cache 大约 1020 个时钟周期,访问 L3 Cache 大约 2060 个时钟周期,而访问内存速度大概在 200300 个 时钟周期之间。
时钟周期是CPU主频的倒数,例如 2GHZ主频的CPU,一个时钟周期是 0.5ns
CPU Cache Line
CPU Cache Line 是每次CPU载入缓存的大小,CPU在读取缓存信息时并非是一次一字节读取而是每次读一个固定字节长度的数据
1 | cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size |

由于他每次是读一块儿数据,那么我们在编写代码时则可以避免多次读取内存,可以将数据内容压缩到64位以内,避免重复读
当我们在使用数组时,例如一个 数据 A 长度 65,则会缓存前64位数组内容,例如从下标0读到63,则不会重复读取内容,那么如果读0 然后 读 64呢?
答案是会重复读内存,他会自动缓存从0开始的一共长度64的数据,那么下标64已经超出这个长度则会重复读内存
那么如果读 0 然后读 2呢,还会重复读内存吗?
答案也是肯定的,如果跳着读他会重复缓存,必须是一个连续的数值才可以利用上这个长度
1 | p : = [3][3]int{{1, 2, 3}, {4 ,5, 6}, {7, 8, 9}} |
上述Go代码中 fmt.Println("echo : " ,p[i][j]) 是在内存中读取连续的数值,而 fmt.Println("echo : " ,p[j][i]) 则并非是在读连续数据,他会不断地请求内存,从而会发现前者的效率更高一些
总结 : 抛开一切因素,读取数据时按照存储顺序来读一定要比任意读效率要高,如果有条件控制数据长度那么可以结合CPU Cache Line 的长度来做一些优化
CPU分支预测
CPU本身是有一个分支预测功能,它相当于一个CPU自带的优化器,当我们在代码中使用if判断的时候,CPU会自行预测他的结果并缓存,那么CPU预测的结果就一定是准确的么,当然不是~
既然CPU的分支预测可以在不知道结果的情况下缓存他认为正确的数据,那么我们在编写代码时则可以适当地让CPU的分支预测更准确,那么也就避免了继续从内存读取数据,避免了多余的操作
代码实现该如何做呢,当一个if语句大多数时间都是 真 的情况下,那么CPU的分支预测将在后续预测中更容易缓存 真 的数据,也可以说,我们的代码尽量让数据保持在一个分支中,可以避免重复读取操作
除了这种CPU自动的分支预测,C语言也提供了一个方法可以告诉CPU大概的结果,从而使CPU更多的缓存某个分支的数据
1 |
|
数据类型和线程绑定
一般情况下,long 类型 要占用更多的空间,所以很多人在使用时更愿意使用 int,但是在CPU Cache line 中确并不如此,如果一些相同的数据经常要一起使用,我们尽量需要把数据长度控制在特定长度之内或者将数据按照指定顺序来存储更好。
数据类型会影响什么,真的是占用内存越小越好吗?
并非如此,现在的服务器更多的是多核CPU,单核CPU则不需要特别注意,多核CPU在处理数据的时候,L1,L2 Cache是独立存在于各个CPU核心的,只有L3 Cache是共享的,既如此,那么L1 和L2的Cache是如何共享信息保持数据一致性?
如果一个进程在不同核心 来回切换,各个核心的缓存命中率就会受到影响,当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问 题,我们可以把线程绑定在某一个 CPU 核心上
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能,从某些程度上来说,亦可以保证数据的一致性问题
多核多线程之间的数据一致性如何保证?现在市面上大多数的CPU核心是通过 MESI 协议来保持数据一致性的,是Modified Exclusive Shared Invalidated的缩写,即是: 已修改 独占 已共享 已失效
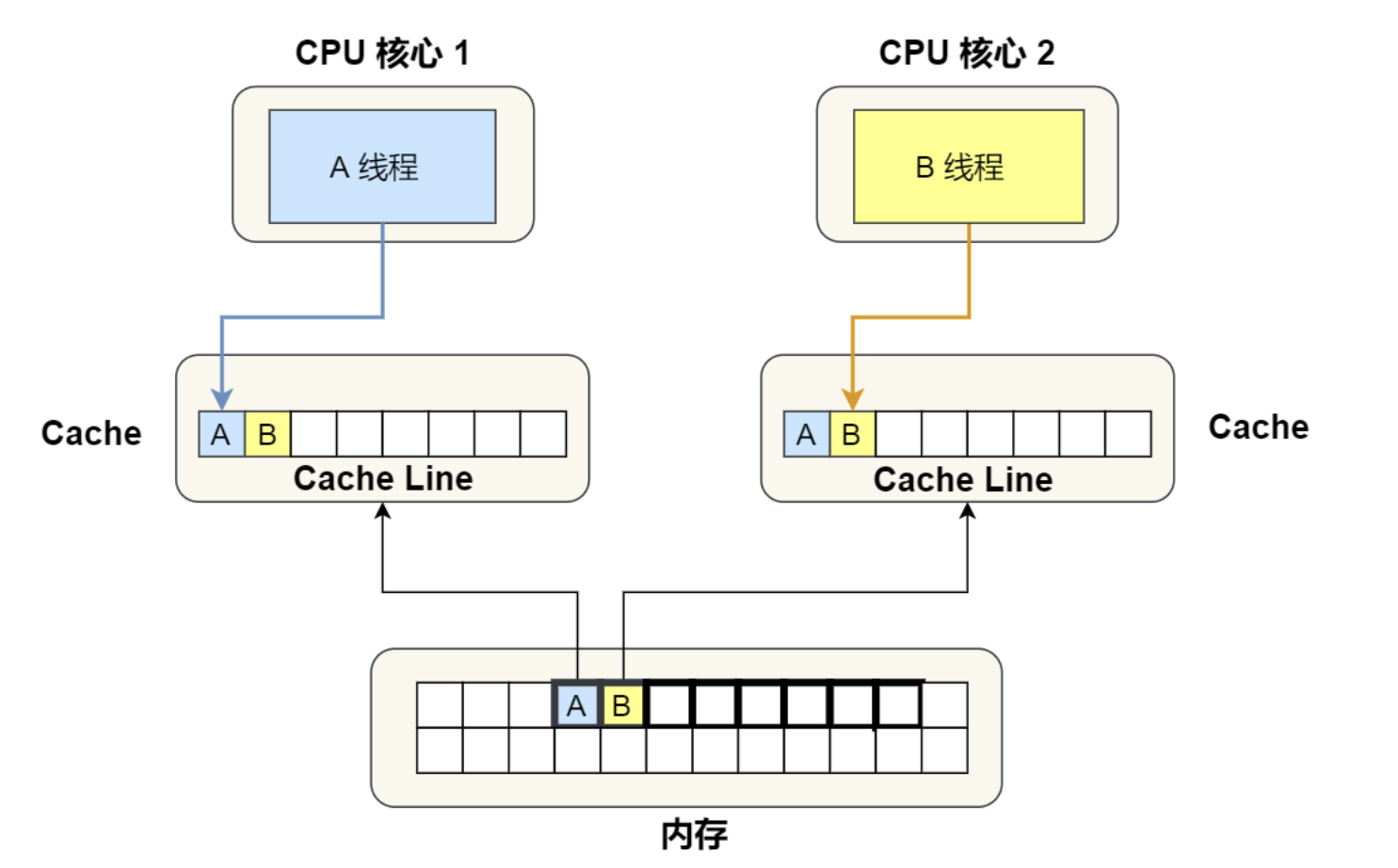
如上,当两个线程都在操作时,A和B都是从内存取出一块儿数据来操作(CPU Cache Line),很多情况下,如果未能保证数据的连续性,A线程就容易拿到B的数据,B也会拿到A的数据,如果A线程操作变量内容时,那么B也需要同时修改才能保证数据的一致性
那么数据的’锁‘该如何保证呢,则是 MESI协议来保证的。
线程A操作变量发生变化时,线程A不会广播写入到内存,而是将数据标识为 已修改,而其他线程则是将数据标记为 已失效,当线程读取数据发现标识为已失效时才会重复读取数据更新数据,否则频繁的刷新数据则失去了CPU Cache的意义
当线程A将已修改的数据写入到内存后,其他线程也更新完数据,那么,将会把数据标记为 已共享
当线程A创建一个数据,其他线程缓存并不存在该数据时则该数据为 独占
如上,当出现越来越多的数据在不断地变化,多个线程操作同一块儿缓存,即使有MESI协议的调度,也不免多了很多操作,所以有些人就想到了用占位更大的字符类型让一个变量占用更多的字节数,从而达到保证线程永远拿到这一块儿数据的时候不会有其他线程的共享数据,而实际上,在多核系统中,也提供了宏定义 __cacheline_aligned_in_smp 来保证数据的长度与CPU Cache Line 保持一致
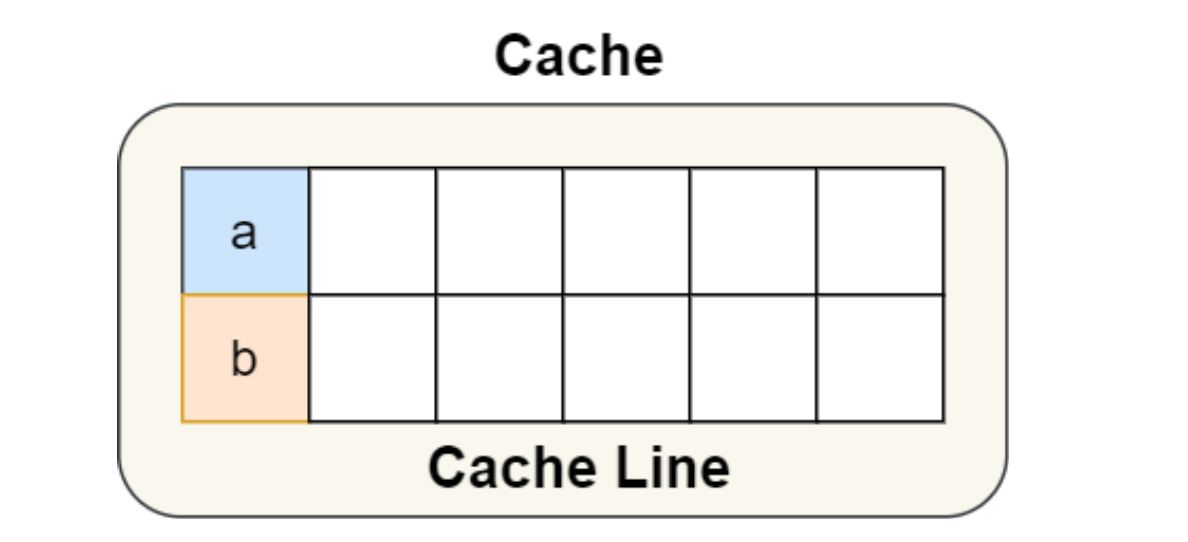
如上,A和B通过宏定义 __cacheline_aligned_in_smp 定义后,字节数会各自占用一块儿,则避免了数据频繁共享的问题
参考
- 小林Coding(图解系统)
近期写一写感谢大佬的电子图书笔记,小白受益良多

